Fig 1: Building connections among sources using a dynamic system.
.
Reasoning is dynamic and spatial. Whether escaping a war zone or watching a suspenseful movie, a person’s understanding of the real world changes over time and space. If machines could present knowledge as we understand it, they’d allow us to immersively connect fragments of information from any resource – whether textual, aural, linguistic, spatial, or visual. They’d allow us to compose new architectures from select pieces of these sources. And eventually, they’d learn from our activities and adapt their rigid reference frameworks to lived situations.
The Virginia Modeling and Simulation Center (VMASC) is building a narrative modeling platform that can do this, in collaboration with Griffith University and the Eastern Virginia Medical School (EVMS). The tool will enablers users to connect and organize information across media, contexts, times, scales and perspectives. To capture the needed dynamic and spatial qualities, the tool is presented in a Unity 3D virtual reality environment. This allows us to present real-world artifacts, such as bodies, environments and events, closer to the forms in which they actually exist.
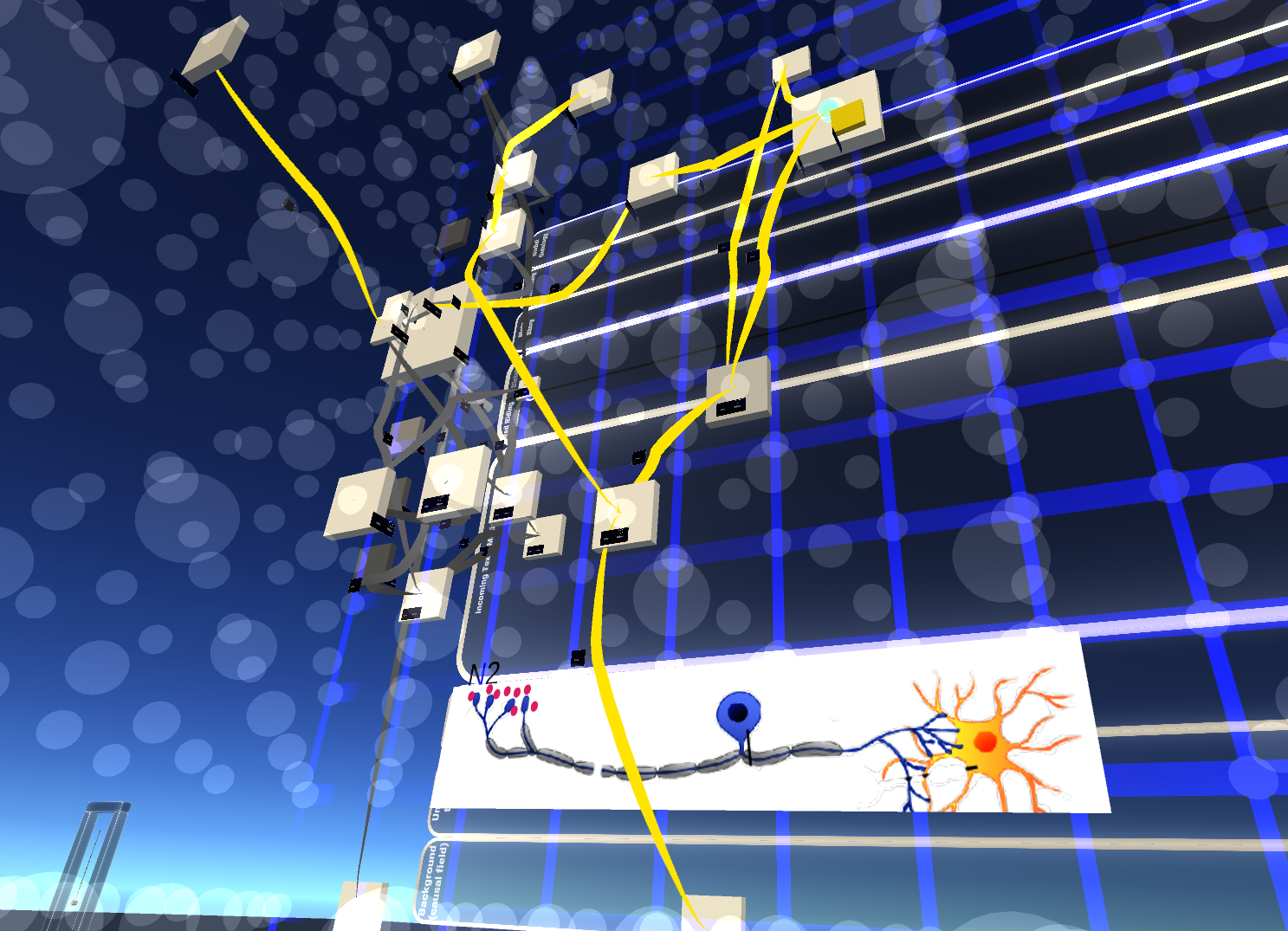
Fig 2: Annotating the animated progress of the HSV virus down the trigeminal nerve, with information in four dimensions.
Our interface and back-end support are based on narrative devices. Narrative structure is more flexible than logic and richer than a list. It enables inferences from many sources to be manipulated until they suit a new purpose. Rather than being halted by the unexpected, a story is fueled by it. These qualities are brought to this new modeling approach.
To allow change to be recorded, we draw an understanding of narrative from cognitive science and conceptual change (David Herman, Peter Brooks, Paul Thagard). Higher-level connective devices such as novelty, metaphor, influence, conflict and transfer can be used to connect sources more flexibly and with a further reach. These special features allow us to visualize how clusters of knowledge are disrupted, re-formed and influence each other. Target domains are the analysis of social media, tracking progress in clinical therapies or managing information across sprawlingly large systems, such as climate science. The eventual goal is for these models to inform machine learning, so that autonomous systems can make new observations as they surf our data oceans.
There are several challenges to developing dynamic representational structures. The most fundamental is the tension between established systems and capturing new, lived qualities. For instance, below is an example of why current formal knowledge models struggle to accommodate adaptive reasoning or novel information. They are usually represented in a manner similar to this –
.
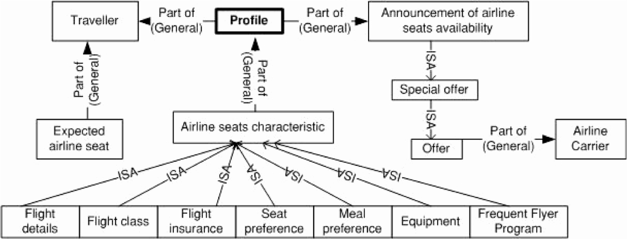
Fig 3: Ontology for a system that seats airplane passengers.
.
Static frameworks like this are the reason that fixed definitions and type systems are used to classify inputs. This is why they can only identify expected and general entities. As a result, many essential aspects of the world slip through their net.
We use narrative-based structures in addition to general frameworks. Instead of solely depending on node-link dependencies, we thus add another tier that shows how channels of information play different roles depending on context. This means more complex and nuanced connections between content can be captured than is possible using the simple node-link structures pictured in Figure 3.
Users will be able to arrange and manipulate this information in an immersive Unity-based VR environment. John Shull is currently adapting Unity to do things it wasn’t originally designed for, including manipulating text, zooming through scales and animating structures as they change.
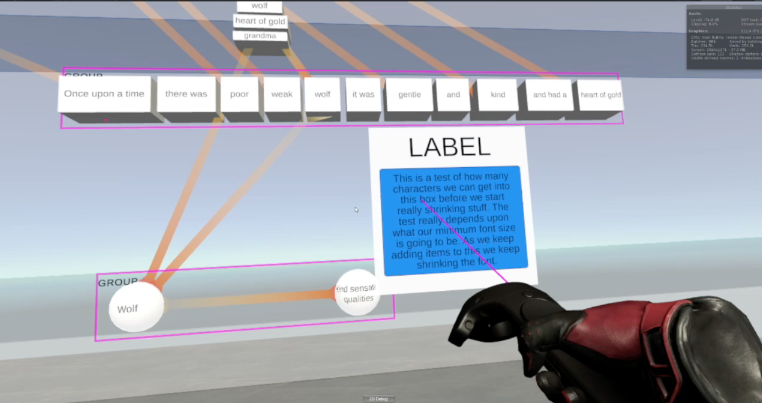
In turn, this requires new way of interacting with the information. New physical user interface gestures are being developed by Alex Nielsen to ensure the actions we use to interact with the interface intuitively reinforce the modeler’s intent.
We are currently developing the platform towards the Hololens 2, in order to ditch the controller paddles and interact directly with our hands.
This project received $50K seed-funding by the National Academies Keck Futures Initiative from 2016-2018 and is now supported by a collaboration between the Virginia Modeling Analytics and Simulation Center (VMASC) at Old Dominion University, the Institute for Intelligent Integrated Systems (IIIS) at Griffith University, and researchers from the Eastern Virginia Medical School (EVMS).
*Collaborators:
Beth Cardier – Eastern Virginia Medical School
John Shull, Saikou Diallo, Alex C. Nielsen – Old Dominion University
Ted Goranson – Griffith University
Niccolo Casas – RISD Rhode Island School of Design; The Barlett College, University College of London
Larry D. Sanford, Patric Lundberg, Richard Ciavarra – Eastern Virginia Medical School.
Advisor:
Matthew Garcia – Brandeis University
Publications for this project can be found here.